Introducing
The One-Token Model
A unified framework for measuring the financial & environmental impact of AI inference at the token level, enabling organizations move beyond estimates & gain real-time visibility into cost, energy and carbon emissions.

Published : December 1st, 2025
Introducing The One-Token Model
A unified framework for measuring the financial & environmental impact of AI inference at the token level, enabling organizations move beyond estimates & gain real-time visibility into cost, energy and carbon emissions.
Published : December 1st, 2025
Introducing The
One-Token Model
A unified framework for measuring the financial & environmental impact of AI inference at the token level, enabling organizations move beyond estimates & gain real-time visibility into cost, energy and carbon emissions.
Published : December 1st, 2025

Introduction
Enterprise adoption of generative AI has expanded rapidly, with recent surveys indicating that approximately 90% of organizations have integrated AI into at least one workflow. Yet, despite this widespread uptake, most enterprises remain confined to exploratory or pilot-stage implementations. This limitation is not due to inadequacies in model capability, or technical abilities, but to the absence of a standardized, rigorous framework for quantifying computational work. Today, there is no dependable, foundational measurement framework for organizations to understand the impact of their AI investments.
In the absence of such a foundational metric, organizations are unable to evaluate efficiency, characterize model behavior, or establish reliable relationships between usage patterns, cost structures, and associated energy or emissions impact. The absence of this measurement foundation prevents enterprises from building predictable budgets, scaling workloads responsibly, and enforcing AI governance with confidence.
This gap shows up in three distinct ways:
1. Measurement of Usage
While leading AI model providers price by API call, token, or GPU hour, there is no industry-wide, deeply-accepted standard that allows organizations to truly understand and compare the compute effort or resource use behind different jobs or workflows.
2. Rising Costs of AI Usage
As models become larger and more complex, and as backend architectures (servers, batch sizes, mixtures of expert models) become more advanced, billing structures grow less transparent for the enterprise buyer. Organizations rarely receive detailed breakdowns of how their usage, prompt complexity, or model choice contribute to total compute cost. This makes budgeting unpredictable and optimization difficult.
3. The Environmental Impact of this Usage
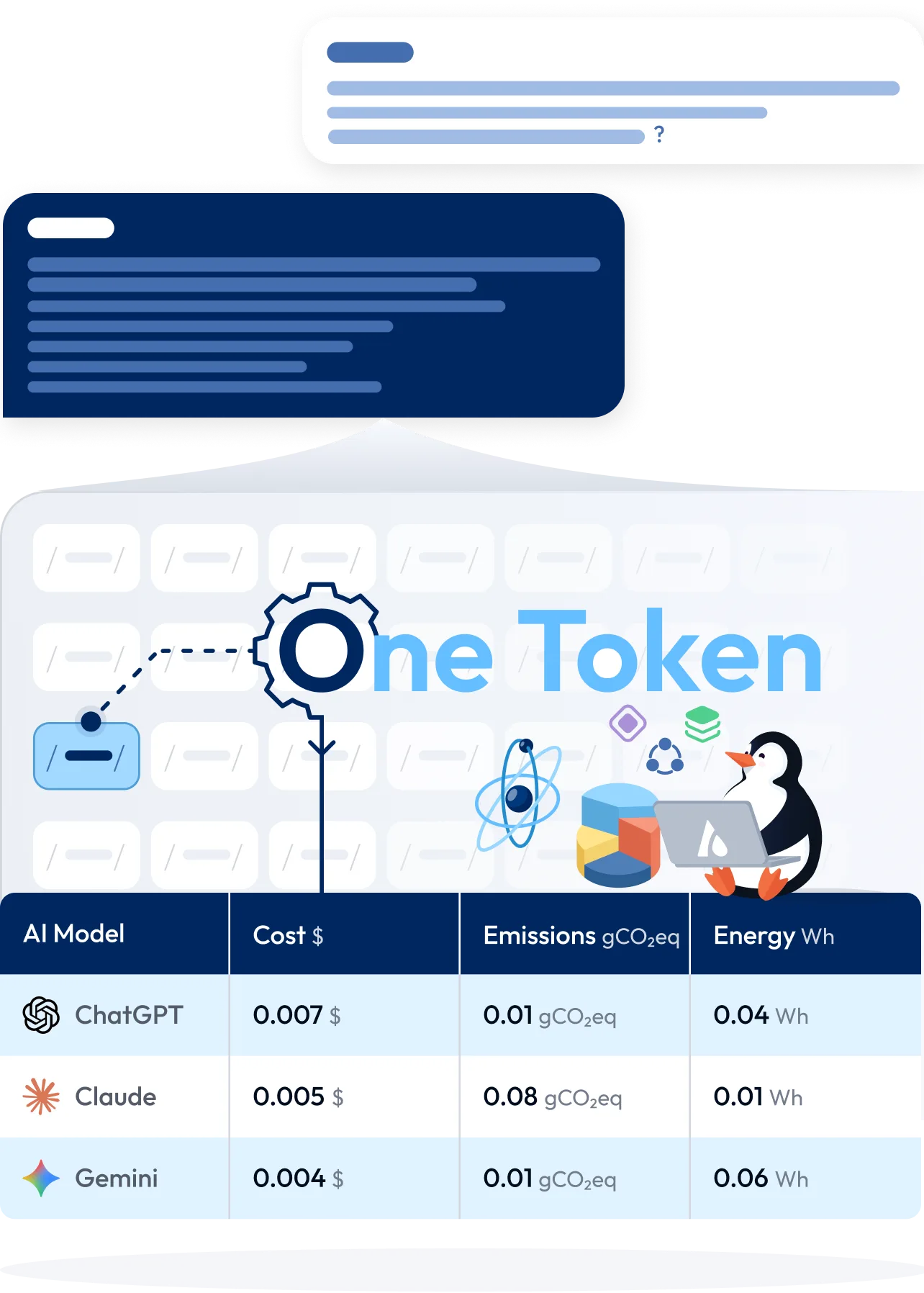
AI’s energy use and carbon footprint are rarely transparent. Google’s disclosure that a median Gemini prompt uses 0.10 Wh and emits 0.02 gCO₂e is directionally useful. But a median value conceals the variability across prompts of different lengths, structures, and complexities, leaving organizations without insight into the full distribution of environmental impact.

The One-Token Model API: Bridging the Measurement Gap
The One-Token Model API provides real-time, per-token cost, performance, energy and carbon measurements for any Al workload. Rather than relying on averages or estimates, organizations can instrument their existing AI pipelines to receive granular impact data for every inference event.
Start Measuring

The One-Token Model API: Bridging the Measurement Gap
The One-Token Model API provides real-time, per-token cost, performance, energy and carbon measurements for any Al workload. Rather than relying on averages or estimates, organizations can instrument their existing AI pipelines to receive granular impact data for every inference event.
Start Measuring
The AI Lifecycle and The Role of a Token
Every meaningful action performed by an AI model today, whether understanding text, analyzing an image, interpreting audio, or generating a response, ultimately manifests as computation over tokens.
Tokens are the atomic units through which large language and multimodal models perceive, process, and produce information. They form the only universal unit that spans evaluation, inference, cost, hardware usage, and environmental impact.


During evaluation, models are tested with structured prompts to measure accuracy, coherence, and task performance. These tests also reveal how many tokens a model must process to achieve a given level of quality. When translated into energy, or cost per token, evaluation benchmarks become multidimensional, allowing organizations to compare not just accuracy but energy and cost efficiency across model versions or configurations.
However, the real impact emerges in inference. Google reported processing 1.3 quadrillion tokens monthly in 2025, a scale so large that raw token counts become abstract. The way to resolve this ambiguity is by translating token volume into quantifiable cost, usage, and energy consumption, turning statistically overwhelming numbers into operationally relevant metrics.
| Provider | Reported Token volume (Monthly, 2025) | Notes/Source |
|---|---|---|
 Google (Gemini / DeepMind) Google (Gemini / DeepMind) | 1.3 Quadrillion (1.3 x 10¹⁵) | Across all surfaces; doubled from 480 trillion in May to 980 trillion in July, reaching 1.3 quadrillion by summer. |
 Open AI (API + ChatGPT) Open AI (API + ChatGPT) | >259 Trillion (API only) | API at >6 billion tokens/min; total including ChatGPT estimated higher but not publicly detailed; 800 million weekly active users. |
 Microsoft (Azure OpenAI / Copilot) Microsoft (Azure OpenAI / Copilot) | 1.7 Trillion (Foundry product) | Specific to Foundry; broader Copilot usage likely higher but no aggregate reported; quotas up to 32 billion for GPT-5 models. |
 Anthropic (Claude) Anthropic (Claude) | ~25 Trillion (estimated) | 25 billion API calls in Q2; assuming ~1,000 tokens per call; 30 million monthly active users. |
The Ubiquitous Token
Tokens are the model’s internal representation of meaning. Just as humans rely on words, models rely on tokens: discrete, structured units that encode linguistic, visual, or auditory information. Because all computation happens on tokens, they become the only unit that measures four critical dimensions: operational throughput and latency, economic pricing, sustainability in terms of energy and emissions, and hardware efficiency as reflected in power draw per token.
By late 2025, a growing body of practice and research places tokens at the centre of how AI is measured, priced, and optimised. Providers increasingly expose token-based limits, routing rules, and pricing tiers. New hardware generations such as Blackwell, MI300, and Gaudi make token-level behaviour far easier to observe through metrics like tokens per second, per watt, and per joule.
This direction is echoed in the Stanford AI Index 2025, which emphasises token-normalised benchmarks for comparing inference cost, efficiency, and carbon intensity. They highlight a substantial reduction in inference costs since 2022, now commonly measured in token units, and encourage hybrid evaluation that pairs token usage with actual outputs. Complementary research on token efficiency, such as the Token Length Control with Dynamic Rewards (TLDR)-style dynamic reward shaping, demonstrates that substantial reductions in token usage are possible without affecting accuracy, particularly for reasoning and maths-heavy tasks.
At the application layer, similar patterns appear in how enterprises design and operate AI products. Teams increasingly treat token usage as a KPI, budgeting and allocating costs in tokens, prompt engineering in RAG pipelines, agent orchestration, caching, and session management. Sparkco AI’s 2025 analysis illustrates this shift, documenting 30–40% token reductions in real deployments through retrieval optimization, pruning, batching, and improved memory management. Emerging frameworks also assess the efficiency of tokenization itself.
These developments reflect a broader move toward understanding how much compute, cost, and energy each token represents.
Tokens in the Context of Providers
Model providers, across closed, and open-source releases, price their APIs (OpenAI, Gemini, Anthropic, Deepseek and others) exclusively in terms of tokens, distinguishing between input tokens (what the user sends into the model) and output tokens (what the model generates) and often adding separate rates for cached/context tokens.. This differentiation of input, output, and context-extension tokens is because each carries a different computational footprint, from attention cost to KV-cache pressure, driving more granular cost models, including surcharges for long contexts or discounted rates for efficient batching and (in the future) low-carbon regions.
Real-time token telemetry is now standard. API users receive real-time token counts, burn-rate signals, and “token waste” diagnostics, enabling prompt optimization, throttling, and model switching. Token behaviour also shapes modern inference scheduling. Modern serving systems: multi-model routing, mixtures of experts, and chip-aware orchestrators use token-arrival rates and tokens-per-joule measurements to size batches, route workloads, andmaintain SLAs across large fleets. Providers additionally, under pressure from the community have begun to disclose energy-per-token and carbon-per-token metrics (see Google’s per token emissions analysis).
In the open-source ecosystem, token-normalised benchmarks (tokens per task, latency per token, and energy per token), are now common across multilingual and multimodal evaluations. (see Hugging Face’s AI Energy Score)
Together, these practices make tokens the provider’s operational reference point for pricing, routing, efficiency, and sustainability.
2025 Token Economics at a Glance
| Model | Input Price (per 1M tokens) | Output Price (per 1M tokens) |
|---|---|---|
| $1.25 | $10.00 | |
| $3 | $15 / MTok | |
| $1.2, prompts <= 200k tokens $4, prompts > 200k tokens | $10.00, prompts <= 200k tokens $15.00, prompts > 200k tokens | |
| $0.19-$0.49 (3:1 blended) | $0.19-$0.49 (3:1 blended) | |
| $0.20 | $0.50 | |
| $0.028-0.28 | $0.42 | |
| $0.4 | $2.0 |






Tokens in the Context of Hardware
At an infrastructure level, every token processed by a model triggers real, measurable work on the accelerator, moving data through memory, running transformer blocks, hitting or missing caches, and drawing power. New GPU and accelerator stacks now expose per-token telemetry, reporting how much bandwidth, cache activity, heat, and power each segment of computation uses. Cloud and on-prem orchestration systems collect this data into live dashboards and sustainability reports, giving operators a detailed view of the physical cost of each token.
This level of visibility has reshaped tooling. OpenTelemetry extensions now treat tokens as first-class units, and FinOps teams combine cost, power and workload metrics to calculate tokens-per-joule, and cost, carbon-per-prompt. These metrics feed internal dashboards, SLAs, and even customer billing. Green routing frameworks (for example, GreenPT’s green router) help to choose the best model for each request, shifting workloads to cleaner regions or delaying inference when the grid is under stress.
Multimodal models add nuance: text tokens, image patches, and audio segments run through different paths, so comparisons often use normalised semantic units or composite efficiency scores to reflect equivalent work. At the same time, operators increasingly attribute part of the hardware’s lifecycle (Scope 3) emissions to inference, giving a fuller picture of carbon intensity. These capabilities are no longer limited to major hyperscalers. Edge devices and local GPUs now ship with SDKs that report tokens-per-joule or carbon-per-prompt directly to end users.
Tokens in the Context of Users
In the context of tokens, “users” primarily refers to the teams, products, and organizations that consume model capacity through APIs or embedded AI workflows, not just individual end-consumers typing into a chat interface.
Enterprise and developer users receive detailed token telemetry from providers, allowing them to allocate compute costs across departments or features, optimise prompts and RAG pipelines, and monitor energy and performance per API call. For SaaS builders and product managers, token consumption directly shapes the economics of their products, even if their customers only see high-level abstractions like “queries processed” or “documents analysed.”
Professional and power users, such as those relying on GitHub Copilot or AI productivity tools, sometimes interact with token limits indirectly through quotas or usage tiers. For them, “fewer tokens” can translate into staying within plan limits or achieving faster interactions, but not always into direct cost savings. In contrast, casual consumer users (like someone using ChatGPT or Copilot on a personal plan) rarely see tokens at all; their experience is governed by fixed envelopes, input caps, or rate limits rather than per-token economics or sustainability benefits. In enterprise environments, internal employees or client users typically never manage tokens directly, but enterprise IT and AI managers do, feeding token metrics into billing, reporting, optimisation, and environmental dashboards.
Across these contexts, tokens matter as an operational, economic, and sustainability metric only for the users who are responsible for or billed by their usage. For others, the effects are indirect: efficiency at the organisational level improves speed, reliability, and sustainability downstream.
To summarize, tracking per token metrics enables users to:
- Allocate compute costs across departments, teams, features, or products with granular accuracy.
- Monitor latency, throughput, and energy usage on a per-API-call basis.
- Optimise prompts, RAG pipelines, agent flows, and caching to reduce unnecessary token generation.
- Compare models, chips, and routing decisions using normalised efficiency metrics (e.g., tokens-per-joule, carbon-per-prompt).
- Manage quotas, usage tiers, and plan limits for professional or power-user scenarios.
- Reveal sustainability and cost insights in enterprise dashboards, green SLAs, or internal reporting.
- Translate token-level behaviour into product-level decisions for SaaS builders and application providers.
See this in action with the One-Token Model API
Our API brings token-level observability into a unified, real-time dashboard, enabling model comparison, prompt optimization, and precise allocation of AI costs across teams, products, and workflows. Organizations can benchmark performance, optimise AI workflows, and operationalise sustainable AI practices at scale.
Explore API
See this in action with the One-Token Model API
Our API brings token-level observability into a unified, real-time dashboard, enabling model comparison, prompt optimization, and precise allocation of AI costs across teams, products, and workflows. Organizations can benchmark performance, optimise AI workflows, and operationalise sustainable AI practices at scale.
Explore API
Deep-Dive into a Token
Across modalities, whether the AI model is reading text, analyzing an image, or listening to audio, it always breaks the input into small, understandable pieces called tokens.


Text Tokenization
Text is decomposed into small units: characters, sub-words, or words, through tokenizers such as OpenAI’s tiktoken, which approximates one token as ¾ of an English word. The model processes these tokens sequentially and produces new tokens one by one.


Audio Tokenization
Digitally, an audio signal is described as a continuous waveform of sound pressure over time. Audio tokenization transforms continuous sound waves into discrete representations, or tokens, that sequence models can interpret.
Some techniques include:
1. Phoneme/Character Tokens (Automatic Speech Recognition) which converts spoken language into text by transforming audio signals into discrete tokens such as phonemes, characters, or words.


2. Codec Tokens (Neural Audio Codecs) like EnCodec (Meta’s) and SoundStream (Google’s) turn audio into sequences of tokens without compromising quality, using vector quantization.
These representations align audio with the same discrete token-based processing, as text.


Image Generation
In digital context, an image is described as a collection of pixels. However, the image generation models don’t see an image as pixels, but as structured information that’s broken into smaller, meaningful representations. These compact representations are called tokens. They help the model understand patterns, textures, and semantics. Popular approaches:
Patch Embeddings: They split an image into uniform, non-overlapping patches, each represented as a token. These tokens act like words in a sentence, allowing the model to process visual information as a structured sequence of discrete units.
For a 224×224 image and 16×16 patch size, this gives (224/16)2=196 patches. Each becomes one token. These 196 tokens collectively describe the entire image, much like how words (tokens) describe meaning in a sentence.


- Discrete Variational Auto Encoder (DVAE) and Vector Quantization: Think of vector quantization as turning image features into predefined buckets. Each bucket stores a representative vector, and the DVAE maps image parts to these buckets to learn consistent, discrete patterns.


- CLIP-Style Contrastive Embeddings: Contrastive models like CLIP learn to align images and text in the same feature space. Each image or caption is converted into an embedding, and these embeddings can then be grouped or discretized into token-like units for other tasks.


Video Generation
The most common way to tokenize videos today is by breaking them into individual frames and pairing them with the corresponding audio. Each frame acts like an image token, while the audio provides temporal context.
For example, models like Gemini process video as a sequence of image tokens interwoven with text and audio information.


To summarize, tokens are the currency of AI. Whenever a company embeds AI into an application: document analysis, summarization, search, chat, content generation, or media processing. Every user interaction becomes a sequence of tokens in and tokens out.
The One-Token Model: Conceptual Framework
The One-Token Model (OTM) quantifies the energy consumed by an LLM during inference and expresses its environmental impact on a per-token basis. It tells you the energy consumption of your token usage, and its consequent emissions.
The OTM works by observing the computation required to process each token, whether text, audio, image, or multimodal, and translating that computation into energy (kWh) and carbon emissions (gCO₂e). Because every interaction with an LLM ultimately reduces to tokens in and tokens out, the token becomes the most precise and universally comparable unit for evaluating the sustainability of AI usage. Frontier models such as those from OpenAI, Anthropic, Google, and Meta already operate internally using tokenization frameworks.


Although the word “token” appears at multiple layers of the AI stack, the One-Token Model unifies them into a coherent structure for measuring energy.
| Category | What They Are | Where Used | Example | OTM |
|---|---|---|---|---|
| Model/Text tokens (Core Level) | Smallest units processed or produced by LLMs | Inside GPT, Claude, Gemini, Llama | "Hello world!" → ["Hello", " world", "!"] | Primary unit for computing energy and CO₂ per token |
| API Billing Tokens | Units used by providers to meter usage | API dashboards, invoices | 2M tokens billed | Connect cost, usage, and energy |
| End-User Tokens | Hidden tokens exchanged during user interactions | Chat interfaces, enterprise apps | A 200-word prompt → 300 input + 400 output tokens | Enables per-user emissions reporting |
| Hardware-Level Tokens | Token-equivalent compute units derived from GPU telemetry | GPUs, TPUs, accelerators | 1,000 tokens → measurable watt-seconds | Links logical tokens to real-time power and carbon intensity |
| Training Tokens | Tokens used during model training | AI labs, lifecycle analysis | 1 trillion training tokens | Represents embodied emissions outside inference |
Accessing the Model Through the One-Token Model API
The One-Token Model API translates the conceptual framework described in this section into actionable, real-time measurements. Developers instrument their inference pipelines and receive per-token energy and carbon data without needing to implement the measurement engine themselves. The API handles all computation internally, returning structured responses with cost, performance, energy (kWh), emissions (gCO_e), and per-token breakdowns for every inference event.
Start API Integration
Accessing the Model Through the One-Token Model API
The One-Token Model API translates the conceptual framework described in this section into actionable, real-time measurements. Developers instrument their inference pipelines and receive per-token energy and carbon data without needing to implement the measurement engine themselves. The API handles all computation internally, returning structured responses with cost, performance, energy (kWh), emissions (gCO_e), and per-token breakdowns for every inference event.
Start API Integration
Example 1: Model/Text Tokens
basic implementation
When a user chats with ChatGPT, their message is broken into tokens that form the prompt. The model then generates a response using N tokens, which remain invisible to the user. The performance, energy and environmental impact of this interaction is estimated by the One-Token Model API.

Example 2: API/Billing Tokens
Developers using APIs from popular LLMs as well as AI powered coding IDEs can view token usage metrics, including the number of tokens exchanged (input, output, and total) per API call or interaction, through their respective dashboards or API responses. The cost, performance, energy, and environmental impact of this interaction is measured and estimated by the One-Token Model API.

Example 3: End-User Tokens
A user writes a 200-word prompt in an enterprise chatbot.
Behind the scenes, the system logs:
300 input tokens processed + 400 output tokens generated.
Although the user never sees these tokens, the organization can attribute emissions back to this specific user or workflow through the One-Token Model API.
Example 4: Hardware-Level Tokens
A data center runs an inference server where 1,000 logical tokens for a single request translate to a measurable watt-second profile on the GPU (power spikes, memory movement, cache hits). The One-Token Model API converts these GPU telemetry traces into carbon intensity per token, enabling real-time hardware-aware emissions estimates.
Example 5: Training Tokens
A model developer reports that a new LLM was trained on 1 trillion tokens. OTM treats these as part of the model’s embodied emissions, distributing the training carbon footprint across all future inference tokens to reflect lifecycle impact, something end users and enterprises can now see in per-token calculations.
Overview of the Methodology
Inference impact is measured by observing how a model exercises compute resources during token generation. The model starts at the hardware layer, where energy is actually consumed, and progressively incorporates model-level and system-level factors to calculate the energy per token and the corresponding carbon emissions.
The OTM is grounded in peer-reviewed literature and validated against established industry methodologies for AI energy measurement. It has been independently extended into a unified, production-scale framework through systematic empirical calibration.


The One-Token Model produces calibrated energy and emissions measurements by accounting for the physical hardware running inference, the characteristics of the model being served, and the observed behaviour of each inference request - simultaneously, not sequentially.
Domain 1: Hardware Utilization
The hardware domain captures the physical energy consumed during inference. This includes accelerator activity at the GPU level as well as non-accelerator infrastructure overhead (CPU, RAM, networking, cooling). The OTM measurement engine incorporates empirically derived baseline power factors for inference-optimized data centre deployments, calibrated against measurements from hyperscaler-class GPU nodes. Where deployment-specific telemetry is available, particularly in on-premise or tightly controlled environments, these baselines can be refined to reflect measured operating conditions. For closed models, the One-Token Model API relies on existing research, experimental data, and industry benchmarks for the hardware utilization metrics.
Domain 2: Model Architecture
The model architecture domain accounts for how a model’s internal structure determines its resource requirements during inference. Key architectural characteristics-including model architectures, and numerical precision settings-directly influence accelerator memory utilization and power draw. The One-Token Model API uses these architectural signals to estimate the computational footprint of a given model configuration during inference.
Domain 3: Inference Dynamics
The inference dynamics domain captures the temporal behavior of the generation process. These metrics define the time window over which energy consumption takes place. The number of generated output tokens provides the denominator for per-token normalization.
Energy and Carbon Estimation
The OTM’s measurement engine combines signals from all three domainsto estimate the total energy consumed during an inference event. Hardware utilization data, model architecture characteristics, and observed inference behaviour are integrated within the One-Token Model API to compute energy consumption in kilowatt-hours. Power Usage Effectiveness (PUE) and other research-backed overhead factors are applied to account for data centre cooling and infrastructure overhead.
| Signal Domain | Description |
|---|---|
| Model Architecture Signals | Characteristics describing how models are structured and executed, including scale, sparsity, and precision configurations |
| Infrastructure Signals | Real-time and profiled data capturing accelerator activity, server-level power consumption, and data centre efficiency characteristics |
| Inference Behaviour Signals | Usage-level dynamics related to time-and token based telemetry signals during real-time inference. |
Carbon emissions are then derived by combining estimated energy consumption with region-specific grid carbon intensity factors. The final per-token impact is obtained by normalizing total emissions by the number of output tokens generated, yielding a granular, comparable unit of environmental impact.
The OTM is aligned with ISO 14064, ISO/IEC 21031 and GHG Protocol guidance
The OTM engine is implemented as a proprietary calibration API. Internal parameters are derived from systematic benchmarking across production inference workloads and are continuously updated from live deployment data. This proprietary engine has been developed through extensive empirical testing, benchmarking against real-world deployments, and continuous calibration against hardware telemetry.
The One-Token Model API exposes the results of this engine without requiring users to implement or maintain the measurement logic themselves.
See this in action with the One-Token Model API
Our API brings token-level observability into a unified, real-time dashboard, enabling model comparison, prompt optimization, and precise allocation of AI costs across teams, products, and workflows. Organizations can benchmark performance, optimise AI workflows, and operationalise sustainable AI practices at scale.
Explore API
See this in action with the One-Token Model API
Our API brings token-level observability into a unified, real-time dashboard, enabling model comparison, prompt optimization, and precise allocation of AI costs across teams, products, and workflows. Organizations can benchmark performance, optimise AI workflows, and operationalise sustainable AI practices at scale.
Explore API
Normalizing Tokens For the OTM
Inference Phases and Why OTM Focuses only on Output Tokens
Every LLM inference request unfolds in two distinct computational phases:
- Prefill (Input Processing): When you submit a prompt, the model first processes all input tokens together in a single forward pass. During this phase, the model builds an internal representation of your request by populating what's called the KV (Key-Value) cache. This phase determines how long you wait before seeing the first word of the response: the "Time to First Token" (TTFT).
- Generation (Output Tokens): After prefill completes, the model begins generating output tokens one at a time. Unlike prefill, each output token requires a complete autoregressive pass through the entire model. The model must reference everything it has processed so far, apply its full reasoning capacity, and produce exactly one new token. Then it repeats this process for the next token, and the next, until the response is complete.
Empirical work, including EcoLogits, ML.ENERGY, AI Energy Score, and independent studies consistently show:
- For many real-world workloads the decode phase (reasoning plus answer generation) often accounts for the clear majority of inference compute, with compute dominated by how long the model ‘thinks’ and how many output tokens it produces.
- Prefill dominates only in very short outputs.
- For many real-world LLM workloads with non-trivial answers, total compute tends to correlate more strongly with the length of the generated output than with the length of the input, although very long prompts or very short outputs can shift the balance toward input-side prefill
For this reason, V1.0 of the OTM attributes emissions primarily to output tokens, because they represent the section of inference where compute, and therefore energy, is concentrated. Focusing on output tokens provides an immediate, practical benefit: OTM can be applied to any single model without requiring cross-provider normalization.Within any individual model, output tokens provide a stable, consistent anchor for measurement because the tokenizer, architecture, and generation pathway all operate under unified internal logic.
Acknowledging the Limitation
We recognize that for practical measurements, many published methodologies sum these roles and report "energy per token" over the union of input and output tokens, which creates a more hardware, and architecture-agnostic metric.
Attribution to output tokens alone, as in our OTM v1.0 approach, is a pragmatic simplification but it may undercount scenarios where large prompts (many input tokens) significantly affect energy use, this often matters for instruction-following or RAG scenarios. Counting only output tokens does make metrics portable across providers and models, but can miss model design differences that affect prefill.
There is a requirement for a consistent measurement unit that faithfully represents computational work. Output tokens are the starting point for energy attribution because they dominate inference compute. But as models evolve, input tokens, modality-specific processing tokens, and internal reasoning tokens will also need to be incorporated into a more complete accounting.
Modern AI usage rarely stays confined to one model or one provider. Organizations evaluate multiple options. Developers compare costs across OpenAI, Anthropic, and Google. Applications route requests dynamically based on workload characteristics.
Furthermore, even under proprietary models, the OTM estimates architectural characteristics based on performance heuristics and validated community research. OTM V1.0 focuses on text-to-text generation and does not yet account for the specific overhead of multimodal inputs.
On Hardware: The model isolates accelerator level power consumption and related metrics as the dominant energy contributor durina inference. Non-accelerator components are represented through empiricall derived baseline power factors based on measurements from inference-optimized data centre deployments. This creates a practical baseline that may not perfectly reflect custom on-premise hardware or alternative accelerators.
OTM Version 1.1: We are actively developing the next iteration, which expands the energy envelope to account granularly for all server components, improves power draw modelling at different utilisation rates, and fully integrates the Antarctica Token normalization layer for cross-provider benchmarking.
The Path Forward
For comprehensive cross-provider analysis, cost optimization, and fair performance benchmarking, the full spectrum of token types, and multi-modal differences across images, video, audio, and cross-provider, must be reconciled into a common measurement framework. For comprehensive cross-provider analysis, cost optimization, and fair performance benchmarking, the full spectrum of token types, and multi-modal differences across images, video, audio, and cross-provider, will be reconciled into a common token framework in the One-Token Model API.
The One Token Model API Principles
The OTM measurement engine is the core that connects the three signal domains described in the conceptual framework. It transforms raw infrastructure telemetry, model configuration data, and observed inference dynamics into calibrated energy and emissions measurements.
The API is built on several foundational principles:
1. Multi-layer integration: The engine simultaneously processes hardware, model, and inference signals rather than treating them independently.
2. Empirical calibration: All internal parameters are derived from systematic benchmarking against real-world inference workloads across multiple hardware platforms and model families.
3. Adaptive baselines: The engine maintains continuously updated baseline profiles that reflect the operating characteristics of major cloud and on-premise deployment configurations.
4. Data validation: When complete telemetry is unavailable (as with closed-model APIs), the engine applies validated statistical models and reference profiles to produce reliable estimates.
5. Ease of use: The entire measurement engine described above is encapsulated within the One-Token Model API. Organizations do not need to build, maintain, or calibrate any of these measurement systems. A single API integration provides per-token financial, performance, energy and carbon data for every inference event, with the engine handling all internal computation, calibration, and normalization automatically.
6. Continuous database expansion: Al providers release new models and tokenizer updates continuously. The One-Token Model API incorporates automated monitoring of new model releases, rapid characterization of new tokenizers and architectures, backward compatibility maintenance, and quality assurance through cross-validation against known workloads and multiple data quality checks.
A Structural Challenge in Enterprise Tokenomics
OTM is designed to be applied independently for each model, provider, and modality. This makes OTM immediately usable in practice. If a developer wants to understand the energy footprint of a prompt executed on GPT-5.1, OTM can measure it. If the same prompt is run on Anthropic Claude Opus, the model can be applied again, producing a separate, model-specific estimate. Each result stands on its own, in the same way that evaluation metrics such as latency, accuracy, or cost are typically compared today: model by model, test by test.
The OTM sometimes uses a simplifying assumption. For instance, for text prompts, approximately four words per token. This assumption is useful in contexts where exact token counts are not yet available, if for example, you are not using your own tokenizer, or because each model requires its own tokenizers, and different measurements for images, videos, and texts.
The OTM in its current version allows teams to reason about orders of magnitude without needing access to provider-specific tokenization. However, this is explicitly an approximation. In any serious deployment, the OTM is intended to operate on the actual token counts reported by each model or inferred from its tokenizer, rather than relying on a fixed 4:1 rule. The approximation can therefore be viewed as a pedagogical bridge, not as a core constraint of the model.
But organizations don't operate in single-model environments. They evaluate options, compare providers, mix modalities, and make purchasing decisions that require apples-to-apples comparisons.Evaluating cross-provider behavior still requires normalized tokens, across input tokens, and behind-the scenes processing tokens, and “output tokens”. Teams can apply the OTM repeatedly across providers and modalities, building a comparable view over time, model by model, use case by use case.
A core challenge in measuring AI inference impact is that one token is not a universal unit of computation within providers. Each AI provider, OpenAI, Anthropic, Google, Meta, Mistral, and others, uses its own tokenizer, vocabulary, and segmentation logic. As a result,identical text, image, audio, or video inputs can yield significantly different token counts across models, even when the underlying computational workload is similar.
| OpenAI (tiktoken) | ~4 Characters/Token |
| Anthropic | ~3.5 Characters/Token |
| Google (SentencePiece) | ~3.8 Characters/Token |
| Meta (Llama Tokenizer) | ~4 Characters/Token |
| Mistral (Custom BPE) | ~3.2 Characters/Token |
Tokenizers differ in vocabulary size, subword construction, merging rules, and handling of whitespace, punctuation, and code. As a direct consequence:
1 OpenAI token ≠ 1 Anthropic token ≠ Google token ≠ Nth provider token
Four problems arise:
- Semantic Non-Equivalence: The same input text produces different token counts, even though the model is performing comparable semantic work.
- Computational Non-Equivalence: Providers encode different amounts of computation per token. For example, some models allocate more attention or memory per token due to architectural choices.
- Modern frontier models operate beyond text:
- Images: patch tokens, DVAE tokens, VQ tokens
- Audio: codec tokens (EnCodec, SoundStream) or phoneme tokens
- Video: tokens per frame, per patch, plus fused audio tokens
- Long reasoning: hidden intermediate tokens
- Tool use: additional model-internal tokens
- Each modality has its own encoding logic, so the computational weight of a "token" varies widely across
- Model families
- Modality types
- Reasoning vs non-reasoning paths
- Provider-specific middleware
To summarize, real enterprise workloads increasingly chain providers("Use Claude for summarization, GPT-4 for structured extraction"), mix modalities ("Analyze this video and generate a written report"), and route through different execution strategies (small-to-large model cascades, MoE expert selection, reasoning mode toggles). Current cost, usage, and energy frameworks cannot reconcile these heterogeneous token types into a common unit. Comparisons become unreliable for tasks like "Analyze this earnings call video and produce a summary" because you cannot meaningfully compare 15,000 video tokens + 500 text tokens in one system against 12,000 unified tokens in another.
To summarize, the OTM is designed around a simple principle: inference compute is overwhelmingly driven by output-generation steps, and output tokens provide a stable anchor for attributing energy and emissions. Within any individual model, this anchor is consistent because the tokenizer, architecture, and decoding pathway operate under a unified internal logic.
But current cost, usage, and energy frameworks do not reconcile these heterogeneous token types into a common unit. This lack of a standardized token unit is a foundational gap in cross-provider sustainability, benchmarking, and cost analysis.
But, the lack of a standardized token unit is a foundational gap in cross-provider sustainability, benchmarking, and cost analysis.
See this in action with the One-Token Model API
Our API brings token-level observability into a unified, real-time dashboard, enabling model comparison, prompt optimization, and precise allocation of AI costs across teams, products, and workflows. Organizations can benchmark performance, optimise AI workflows, and operationalise sustainable AI practices at scale.
Explore API
See this in action with the One-Token Model API
Our API brings token-level observability into a unified, real-time dashboard, enabling model comparison, prompt optimization, and precise allocation of AI costs across teams, products, and workflows. Organizations can benchmark performance, optimise AI workflows, and operationalise sustainable AI practices at scale.
Explore API
The Antarctica Token
The Antarctica Token (AT) serves as this additional normalization layer.
It is defined as a normalized unit of LLM computational work, independent of provider tokenizer differences.
An Antarctica Token represents the standardized computational effort required to process or generate one unit of semantic content, normalized across tokenization methods, model architectures, languages, and modalities.
The Antarctica Token provides a:
1. Provider-Agnostic Equivalence
Effective normalization requires conversion mappings for every major model provider and architecture pattern. The Antarctica Token framework maintains the most extensive database of provider-to-normalized token conversions currently available. This database includes:
All major closed-source providers: OpenAI, Google, Anthropic, Meta, xAI, and others.
Leading open-source model families: Mistral, DeepSeek, and others.
2. Computational Grounding
The AT Framework works on a database built through systematic empirical testing rather than only theoretical assumptions. For each provider and model, the framework measures:
- Full-Cycle Token Accounting tracks total throughput from ingestion to generation, ensuring complete visibility into cost and usage across the entire lifecycle.
- Architectural Resource Profiling analyzes underlying model characteristics and computational weight to optimize performance allocation without manual tuning.
- Adaptive Compute Pathways differentiates between standard processing and complex logic flows, routing requests efficiently based on required cognitive load.
- Unified Multimodal Abstraction standardizes the consumption and generation of diverse media types into a single, cohesive accounting layer, regardless of format.
- Semantic Density Evaluation assesses the information richness of the payload to adjust processing expectations based on the complexity of the content.
- Comparative Infrastructure Benchmarking provides contextual performance data against market standards to validate efficiency and cost-effectiveness.


3. Continuous Database Expansion
AI providers release new models and tokenizer updates continuously. Maintaining accurate normalization requires ongoing measurement and database updates. The Antarctica framework incorporates:
- Automated monitoring of new model releases
- Rapid characterization of new tokenizers and architectures
- Backward compatibility maintenance as older models are deprecated
- Quality assurance through cross-validation against known workloads, and multiple data quality checks.
This operational infrastructure, the continuous process of measuring, validating, and updating conversion mappings, ensures the Antarctica Token remains a stable currency in a volatile ecosystem.
A normalized standard is only as valuable as its accessibility to the systems that need it. The theoretical rigor of the One-Token Model must be translated into actionable telemetry within real-world IT environments. These pathways allow organizations to ingest normalized metrics directly into their existing stacks, and apply the OTM seamlessly, regardless of whether they control the hardware or rely on third-party vendors. This brings us to the three architectural models for deployment.
How The OTM Integrates Into Your AI Stack
The One Token Model is designed to meet organizations wherever they are in their AI deployment. Whether your team calls OpenAI’s API from a product backend, runs open-source models on your own GPUs, or operates a mix of both, the OTM plugs into your existing workflow without requiring changes to your model serving infrastructure, your application code or your choice of provider.
This section describes 3 integration paths. The One-Token Model API adapts its data sources, and estimation approach based on the level of telemetry available, ensuring that every organisation, from a 2 person startup calling an OpenAI or Claude API to a large enterprise running fine-tuned models on a private GPU cluster, receives actionable financial, performance, energy and carbon data.
1. When you call a provider’s API
For teams using OpenAI, Anthropic, Gemini, or any hosted model API
This is the most common setup in production today. Your application sends prompts to a provider’s API and receives completions. You have no visibility into the GPUs or the model’s internal architecture. The provider’s API is a black box.
The One-Token Model API works alongside your existing API calls and applies the methodology. There is no need to change providers, or access hardware you don’t control.


2. When you host your own models
For teams running open-source LLMs on their own GPUs or cloud instances
Many organizations host open-source models such as Llama, Mistral, DeepSeek, Falcon, and others on their own infrastructure, whether on cloud GPU instances (AWS, GCP, Azure, RunPod) or on-premise servers. In these deployments, the organizationmanages both the model, and underlying compute which means the One-Token Model API can access complete hardware telemetry and derive the highest-resolution measurements.
Because the hardware is monitored directly, with the One-Token Model API’s real-time observability, the output contains actual measurements rather than estimates, for every API call.


3. When you run both
For organizations using a mix of provider APIs and self-hostel models
Most mature AI deployments don’t fit neatly into a single category: a team might route summarization tasks to Claude or OpenAI, structured extraction to a self-hostel Llama instance, and image analysis to Gemini, all within the same product. The sustainability, cost and performance data for these workloads needs to appear in a single view, measured consistently regardless of whether the model runs on your hardware or someone else’s.
The hybrid integration of the One-Token Model API combines both these approaches. This means an engineering lead can compare 100+ metrics related to a Claude API call against a self-hosted Llama call for the same task, normalized, consistent, side by side. It also means AI sustainability reporting covers the entire AI inference footprint.


Applications of the One-Token Model
The OTM applies to wherever Al inference creates cost, consumes energy, or produces emissions, which is to say, everywhere Al is used. This section describes the three primary contexts in which the OTM delivers value:


1. Understanding what your AI usage actually costs
For individual developers and power users, every prompt has a cost, metrics to understand its performance, an energy footprint, and an emissions profile, which until now, most users had no visibility into. The OTM helps the user of AI get the data and insights needed to make better decisions with their AI usage.
When a developer using the One-Token Model API sees these numbers in real-time, they start making informed decisions: Does this prompt need to be this long? Is the model generating unnecessary tokens? Would a smaller model produce comparable results at a lower cost and lower environmental impact.
For individual users interacting with a chat-based LLM, OTM can measure the per-prompt impact of an inference event using output tokens as the primary unit. Tools built on top of the methodology (such as lightweight instrumentation layers or prompt-side extensions) can help users understand:
For enterprises, individuals request compounds. Organizations processing thousands of requests per day can see, at a glance, which models, environments, and team members are driving the highest spend and emissions. This enables per-department cost allocation, identification of wasteful patterns (such as failed requests that consume compute without producing output), and data-driven budgets for Al usage. Sustainability teams can extract the data needed for ESG reporting. Engineering managers can identify which workflows are efficient and which need optimization.

For enterprises, individuals request compounds. Organizations processing thousands of requests per day can see, at a glance, which models, environments, and team members are driving the highest spend and emissions. This enables per-department cost allocation, identification of wasteful patterns (such as failed requests that consume compute without producing output), and data-driven budgets for Al usage. Sustainability teams can extract the data needed for ESG reporting. Engineering managers can identify which workflows are efficient and which need optimization.
2. Hardware-Level Monitoring
For organizations running self-hosted models, the OTM connects usage directly to physical activity at the hardware layer. Using accelerator and server-level metrics captured through direct monitoring, the methodology produces a real-time mapping between each token generated and its energy and carbon footprint. This enables infrastructure teams to identify underutilised GPUs, detect power spikes associated with specific workloads, and make informed decisions about hardware procurement and fleet sizing. The data is measured from the actual hardware, providing ground-truth accountability for infrastructure costs and environmental impact.


3. Cross-Provider Benchmarking
Today, organizations choose between Al providers based primarily on output quality and price per token. But price per token tells an incomplete story, it says nothing about energy efficiency, carbon intensity, or how computational effort varies by region and architecture. The OTM enables consistent comparisons across providers.
See this in action with the One-Token Model API
Our API brings token-level observability into a unified, real-time dashboard, enabling model comparison, prompt optimization, and precise allocation of AI costs across teams, products, and workflows. Organizations can benchmark performance, optimise AI workflows, and operationalise sustainable AI practices at scale.
Explore API
See this in action with the One-Token Model API
Our API brings token-level observability into a unified, real-time dashboard, enabling model comparison, prompt optimization, and precise allocation of AI costs across teams, products, and workflows. Organizations can benchmark performance, optimise AI workflows, and operationalise sustainable AI practices at scale.
Explore API
Optimization Using the One-Token Model
The application of the One-Token Model across usage, hardware, and provider layers enables organisations not only to measure impact but to translate those measurements into operational, economic, and environmental improvements. By exposing how efficiently tokens are produced, and used, whether in API-driven applications or self-hosted deployments, OTM provides the observability needed to guide optimization strategies. These strategies typically centre on three outcomes: cost reduction, performance efficiency, and emissions minimization.


Case Study: Improving Inference Efficiency in an Enterprise Deployment
A mid-sized organisation integrates an LLM-based assistant into its internal analytics platform. After an initial period of adoption, the engineering team observes that inference-related cloud costs and GPU activity are increasing at a rate disproportionate to the growth in user queries. To understand the source of the discrepancy, the organisation deploys the One-Token Model with the AT API, to monitor how much computational work is being performed per token and how efficiently that work is converted into user-visible responses.
Establishing a Baseline
Using OTM instrumentation, and the AT API, the team captures real-time metrics such as:
These measurements reveal the energy cost per token and highlight variations in efficiency across workloads and times of day. This baseline becomes the reference point for targeted interventions.
Targeted Optimization
Targeted Optimization with a clear view of the computation associated with each token, the organisation implements improvements along three dimensions:
Analysis shows that the system consumes approximately 0.002 kWh per output token. By adjusting model configurations, introducing modest batching during peak periods, and refining prompt structures to reduce unnecessary generation, the team reduces this to 0.0015 kWh per token. The improvement translates into a 25% reduction in monthly GPU-related energy expenditure.
OTM reveals that certain GPUs deliver significantly better performance-per-watt ratios for the same workload. The inference scheduler is updated to route requests dynamically toward the most efficient hardware, increasing effective throughput by roughly 12% and improving request latency without additional compute. At the usage level, better prompt engineering, and API usage is driven by insights provided by the OTM.
Lower power draw during inference allows the system to scale down inactive GPUs during off-peak hours. When combined with the cloud provider’s PUE characteristics, this reduces quarterly emissions by approximately 125 kg CO₂e. The reduction results not from offsetting but from structural efficiency gains .
For a production ready
implementation of the One-Token
Model API,
reach out to: contact@antarcticaglobal.com
See this in action with the One-Token Model API
Our API brings token-level observability into a unified, real-time dashboard, enabling model comparison, prompt optimization, and precise allocation of AI costs across teams, products, and workflows. Organizations can benchmark performance, optimise AI workflows, and operationalise sustainable AI practices at scale.
Explore API
See this in action with the One-Token Model API
Our API brings token-level observability into a unified, real-time dashboard, enabling model comparison, prompt optimization, and precise allocation of AI costs across teams, products, and workflows. Organizations can benchmark performance, optimise AI workflows, and operationalise sustainable AI practices at scale.
Explore API
Conclusion
As AI becomes more deeply embedded in products, workflows, and infrastructure, organisations need transparent and consistent ways to understand the computational, economic, and environmental consequences of their AI usage. The One-Token Model responds to this need by grounding measurement in the most consequential unit of inference, tokens, and linking that unit directly to the hardware activity, and provider architectures that drive energy consumption and emissions.
This whitepaper represents an effort in consolidation. We have synthesized insights from fragmented research, benchmarks, and disparate methodologies into a unified, systematic framework. By combining hardware-aware estimation with a normalized representation of token-level compute, the OTM establishes a common analytical layer for evaluating AI workloads across open-source, hybrid, and proprietary environments. This gives organisations a clearer basis for decisions related to model procurement, budgeting, capacity planning, and sustainability reporting.
At Antarctica, our core value is bringing radical transparency and measurable value to every company deploying AI. We believe that sustainability, FinOps, and operational efficiency are not opposing goals but shared outcomes. Our mission with the OTM is to make Sustainable AI actionable inside organizations, ensuring that the growing body of research is not merely theoretical, but is implemented to drive tangible impact.
When deployed in production systems, the OTM supports operational optimisation: reducing cost, improving performance efficiency, and lowering emissions without constraining capability. The OTM is a living standard. We are already actively developing Version 1.1, which addresses the limitations identified in this paper to provide an even more granular view of inference. V1.1 will expand the energy envelope to strictly account for CPU, RAM, and networking overhead, and will fully integrate the Antarctica Token, our normalization layer designed to make cross-provider benchmarking consistent.
The need for reliable, cross-provider measurement standards will only grow as AI becomes more ubiquitous and heterogeneous. We are now moving from consolidation to application. The One-Token Model represents a step toward that standardisation by aligning operational clarity with environmental responsibility, offering a practical and scientifically grounded path to understanding how modern AI systems consume resources and deliver value.
Sources
- Rincé, Samuel and Banse, Adrien (2025). EcoLogits: Evaluating the Environmental Impacts of Generative AI . Journal of Open Source Software, 10(111), 7471. DOI: 10.21105/joss.07471
- The state of AI in 2025: Agents, innovation, and transformation
- Measuring the environmental impact of AI inference
- Gemini Enterprise: The new front door for Google AI in your workplace
- NVIDIA Blackwell Leads on SemiAnalysis InferenceMAX v1 Benchmarks
- Testing AMD's Giant MI300X
- Model Performance Data for Intel® Gaudi® 3 AI Accelerators
- The 2025 AI Index Report
- Understanding and Improving Token-Efficiency of Reasoning Models
- Measuring the environmental impact of delivering AI at Google Scale
- Hugging Face: AI Energy Score
- Semantic conventions for generative AI metrics
- GreenPT: Green Router
- The Real Carbon Cost of an AI Token
- What are tokens and how to count them?
- OpenAI's Tiktoken
- EnCodec: High-fidelity Neural Audio Compression
- SoundStream: An End-to-End Neural Audio Codec
- Environmental Impacts of LLM Inference
- Salesforce Joins Technology and Academic Leaders to Unveil AI Energy Score Measuring AI Model Efficiency
- Hugging Face: AI Energy Score Leaderboard
- How Hungry is AI? Benchmarking Energy, Water, and Carbon Footprint of LLM Inference
- BoaviztaAPI: An API to access Boavizta's methodologies and data
- The ML.ENERGY Benchmark: Toward Automated Inference Energy Measurement and Optimization
- Artificial Analysis: Independent analysis of AI
- Empirical Measurements of AI Training Power Demand on a GPU-Accelerated Node
- How useful is GPU manufacturer TDP for estimating AI workload energy?
- Power consumption of a specific NVIDIA data center GPU
Let’s talk tokens
Discover how smarter token usage can lower your AI costs and footprint.
