You are flying blind on AI.
Token counts and a total bill are all your AI provider offers.
The financial, operational, and environmental reality of your AI usage stays out of reach.
What you don’t see




Financial Traceability
Which team, which model, which request drove that cost? There's no way to know.
Operational Optimization
Is your production usage efficient, or is it quietly burning compute? No visibility.
Environmental Accountability
Your AI workloads consume energy and emit carbon. You have no way to measure either.
You are flying blind on AI.
Token counts and a total bill are all your AI provider offers. The financial, operational, and environmental reality of your AI usage stays out of reach.

What you don’t see
Financial Traceability
Which team, which model, which request drove that cost? There's no way to know.
Operational Optimization
Is your production usage efficient, or is it quietly burning compute? No visibility.
Environmental Accountability
Your AI workloads consume energy and emit carbon. You have no way to measure either.


What your provider
cannot show you.
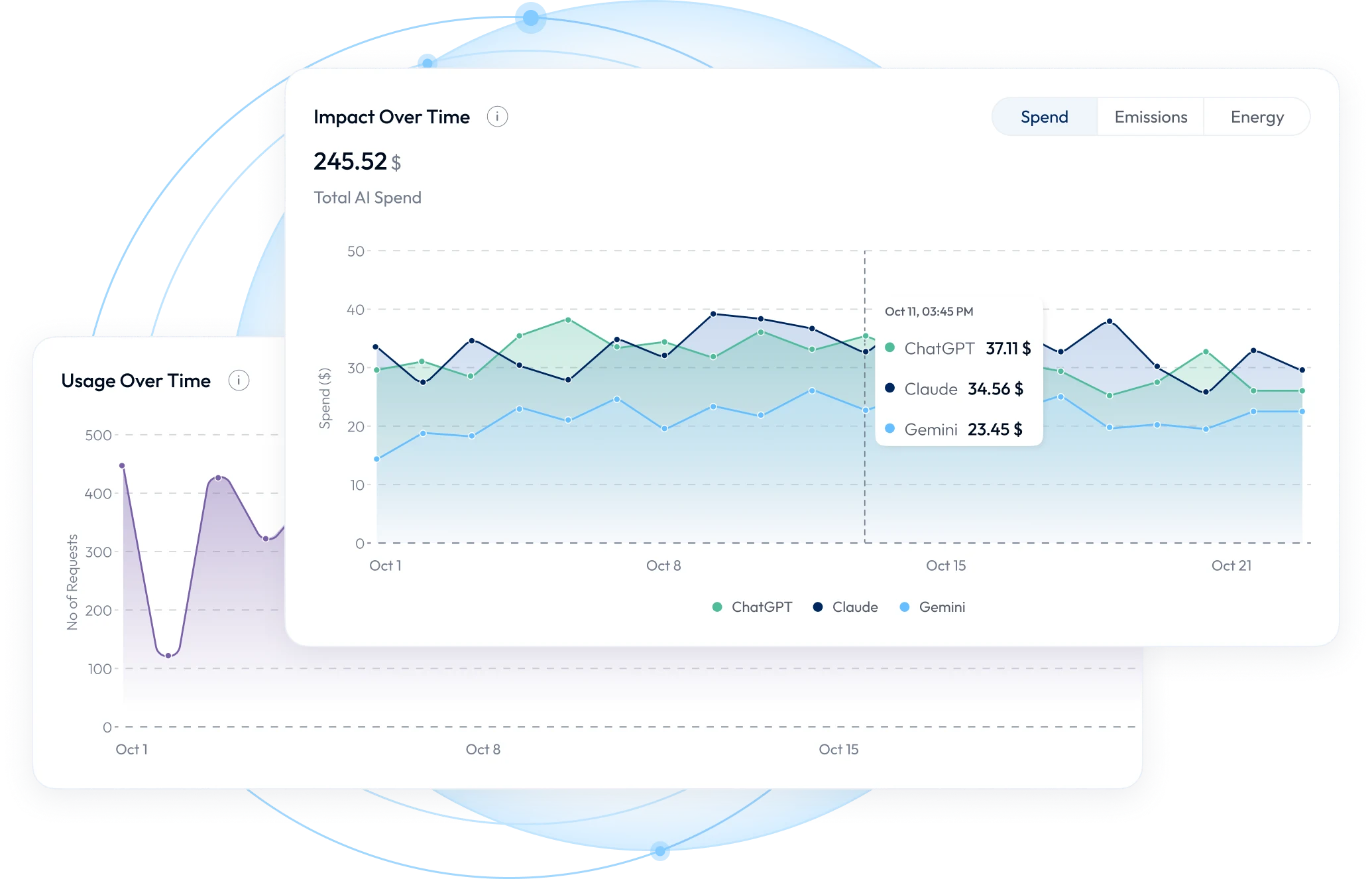
Antarctica captures over 100 real-time metrics per AI request, from cost per token to carbon per inference, giving your organization the telemetry it needs to govern AI at scale.
Antarctica API

Financial
Know exactly what every request costs, who generated it, and which models are driving your bill.
Operational
Track performance, efficiency, and usage patterns across every model, developer, and environment.
Environmental
Measure the energy consumption and carbon footprint of your AI workloads at the request level.



How it works.
Generate your key, plug in the API and start measuring instantly.

Generate API Key
Create an environment-specific OTM key inside the Antarctica dashboard.

Assign Environment
Tag requests as production, Dev or QA to segment spend from the start.

Add Developer IDs
Assign unique identifiers per developer. Every call becomes attributable.

Integrate OTM API
Drop the OTM API along-side your existing AI provider call. No re-architecture needed.
1
Generate API Key
Create an environment-specific OTM key inside the Antarctica dashboard.
2
Assign Environment
Tag requests as production, Dev or QA to segment spend from the start.
3
Add Developer IDs
Assign unique identifiers per developer. Every call becomes attributable.
4
Integrate OTM API
Drop the OTM API along-side your existing AI provider call. No re-architecture needed.
The closed models,
finally open to measurement.
Full telemetry across all proprietary models.










What you get with Antarctica.
Everything you need to gain visibility, control costs and improve AI efficiency at scale.
Per-Request Intelligence
Every AI request is broken into input tokens, output tokens, cost, latency, model, developer and environment, inspectable individually.
Token-Level Cost Control
Input and output tokens measured and attributed separately, giving you the granularity to identify inefficient prompts before they compound.
Model Benchmarking
Compare models and providers side by side on cost, token, patterns, latency, and energy impact. Evidence-based procurement, not assumption.
Developer Attribution
Every request carries a developer identifier. Usage cost, and behavior tracked per person, accountability built into the infrastructure.
Environment Segmentation
Production, Dev and QA isolated from the first request. Prevent cost leakage from experimentation. Support internal governance requirements.
Environmental Measurement
Token activity translated into energy consumption and carbon emissions per request, per token, at the same granularity as cost data.









The One-Token Model.
The world's most advanced AI measurement methodology, recognized by 8 international bodies.
The intelligence behind
The One Token Model quantifies the energy consumed during AI inference and expresses its financial and environmental impact on a per-token basis.
It operates at every layer of the AI stack, from the hardware that runs inference to the model processing each token, translating usage into cost, energy, and carbon data without requiring access to provider infrastructure.
It is the scientific foundation behind every metric Antarctica surfaces.
“The missing piece in the AI puzzle.”




Enterprise-grade security.
Complete enterprise-grade API key management and full access control.

Data Privacy and Security
IP allowlist and mTLS network controls
Environment specific keys
SOC 2 compliance
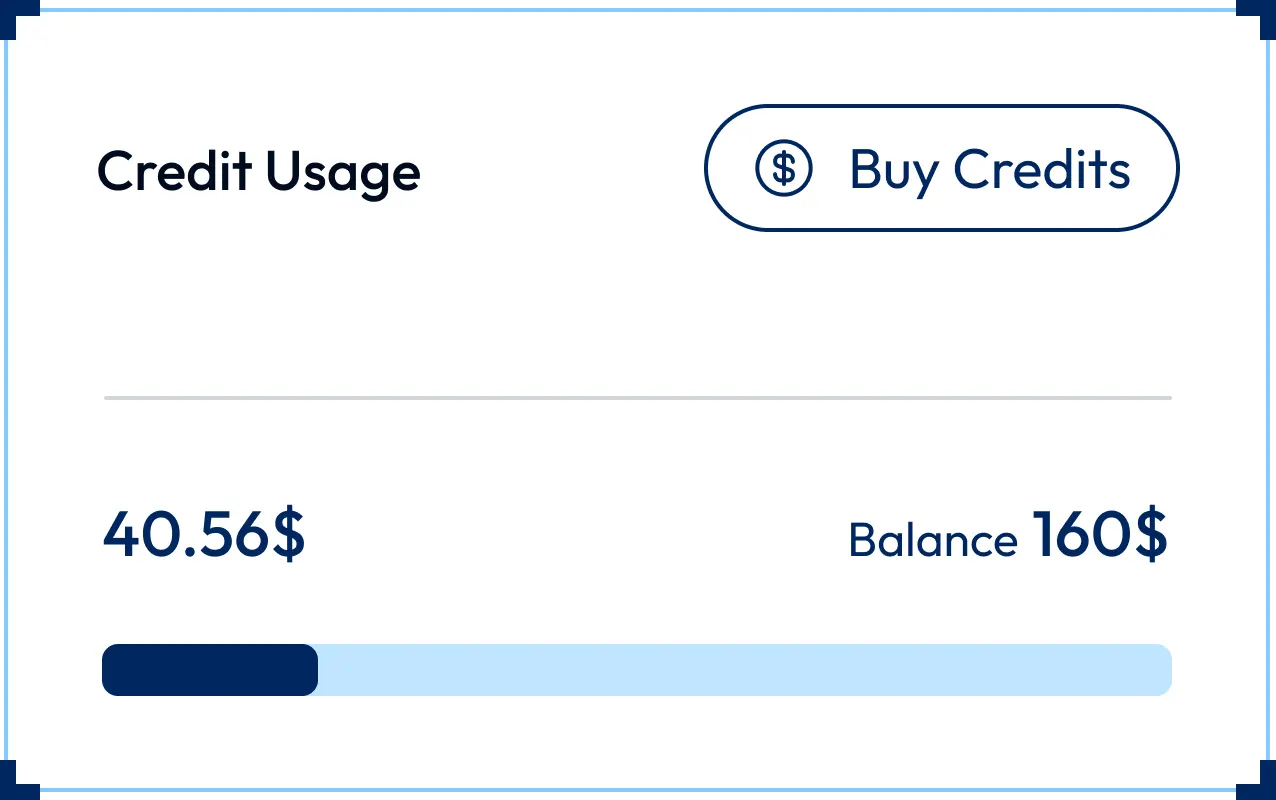
Administrative Governance
Track usage and balance per API key
Full audit trail and transparency
Role-based access controls
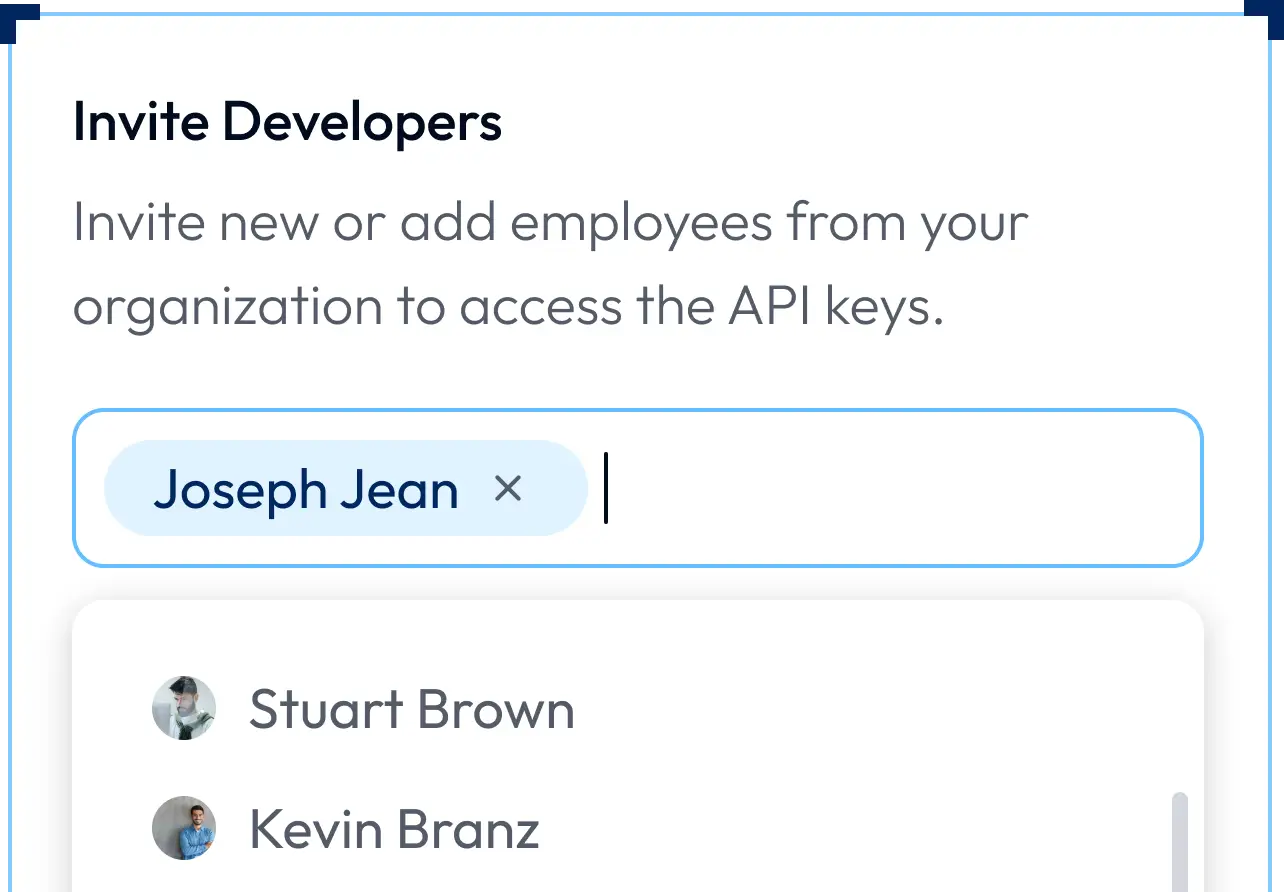
Developer Attribution
Unique identifier for each developer
Granular usage and cost analysis
Prompt vs. response analysis
Control over every AI request.
Automated collection of detailed telemetry for every API request.

Cost Anomaly Detection
Identify abnormal cost spikes and prevent inefficient prompts from scaling unnoticed.
Developer Accountability
Analyze prompt patterns across developers and guide teams toward more efficient prompting.
Track Carbon Emissions
Quantify emissions at the token level and align AI usage with sustainability goals.
Control over every AI request.
Automated collection of detailed telemetry for every API request.
Cost Anomaly Detection
Identify abnormal cost spikes and prevent inefficient prompts from scaling unnoticed.
Developer Accountability
Analyze prompt patterns across developers and guide teams toward more efficient prompting.
Track Carbon Emissions
Quantify emissions at the token level and align AI usage with sustainability goals.
Improved performance and efficiency.
Compare requests to identify the most cost-efficient, energy-efficient and high-performing usage patterns.
Model Benchmarking
Reduce unnecessary token usage and choose the most cost-effective models.
Prompt Efficiency
Identify and refine prompts that generate excessive tokens to reduce wastage.
Energy Optimization
Understand energy usage per request and optimize for efficiency.
Improved performance and efficiency.
Compare requests to identify the most cost-efficient, energy-efficient and high-performing usage patterns.

Model Benchmarking
Reduce unnecessary token usage and choose the most cost-effective models.
Prompt Efficiency
Identify and refine prompts that generate excessive tokens to reduce wastage.
Energy Optimization
Understand energy usage per request and optimize for efficiency.
Everything your team needs to know before deciding.
Your provider gives you token counts and a total bill. Antarctica attributes every request to a model, a developer, and an environment, giving your finance team the granularity to understand what is driving AI spend, not just how much it is.
Most clients identify addressable waste within the first two weeks of integration. Inefficient prompts, oversized model choices, and uncontrolled development spend typically surface immediately once request-level attribution is in place.
Yes. Because Antarctica tracks consumption in real time at the request level, your finance and engineering teams can model spend trajectories before they reach the invoice, not after.
No. Antarctica sits alongside your existing AI provider calls. There is no change to your provider, your models, or your infrastructure. It adds the measurement layer your provider was never designed to give you.
Integrations & API
Got more questions? We’ve got the answers.
How does the integration work technically?
You add a single API call alongside your existing AI provider call. No re-architecture, no change to your provider setup, no new infrastructure. Every subsequent AI request is automatically enriched with the telemetry Antarctica captures.
Do we need to change our AI provider or models to use Antarctica?
No. Antarctica works with your existing providers and models. You keep calling OpenAI, Anthropic, or Google exactly as you do today, the One Token Model API runs in parallel and captures the data your provider never surfaces.
How do we manage access across multiple teams and environments?
Antarctica issues environment-specific API keys for Production, Dev, and QA. Each key can be activated, deactivated, and restricted by IP range independently, giving your security and engineering teams full control over who can generate telemetry and where.
What happens if the Antarctica API is unavailable?
The One Token Model API is designed so that your AI provider calls are never blocked or degraded by Antarctica. Measurement runs in parallel, your application continues to function regardless of Antarctica’s availability.
Does Antarctica store our prompts or model outputs?
Antarctica captures telemetry metadata, token counts, latency, cost, energy, and carbon, not the content of your prompts or responses. Your data stays within your infrastructure.
Integrations & API
Got more questions? We’ve got the answers.
How does the integration work technically?
You add a single API call alongside your existing AI provider call. No re-architecture, no change to your provider setup, no new infrastructure. Every subsequent AI request is automatically enriched with the telemetry Antarctica captures.
Do we need to change our AI provider or models to use Antarctica?
No. Antarctica works with your existing providers and models. You keep calling OpenAI, Anthropic, or Google exactly as you do today, the One Token Model API runs in parallel and captures the data your provider never surfaces.
How do we manage access across multiple teams and environments?
Antarctica issues environment-specific API keys for Production, Dev, and QA. Each key can be activated, deactivated, and restricted by IP range independently, giving your security and engineering teams full control over who can generate telemetry and where.
What happens if the Antarctica API is unavailable?
The One Token Model API is designed so that your AI provider calls are never blocked or degraded by Antarctica. Measurement runs in parallel, your application continues to function regardless of Antarctica’s availability.
Does Antarctica store our prompts or model outputs?
Antarctica captures telemetry metadata, token counts, latency, cost, energy, and carbon, not the content of your prompts or responses. Your data stays within your infrastructure.